Aangemaakt op 14 juni 2023. laatst gewijzigd op 21 July 2024 om 14:04
Exploratie dataset Brabantse huwelijken
De BHIC heeft een dataset ter beschikking gesteld in xml met alle huwelijksakten van Brabantse gemeenten tussen 1811 en 1943. Ook gemeenten die zijn ontstaan of verdwenen door een gemeentelijke herindeling worden apart vermeld.
Hieronder beschrijf ik bewerkingen van de dataset om de volgende aspecten van de dataset te bekijken.
- De relatie tussen percentage Belgische en Duitse bruiden en bruidegoms en de afstand tot de grens van de gemeente waar ze getrouwd zijn.
- Een eerste indruk van cijfers per gemeente, in dit geval het percentage Belgische bruiden en bruidegoms in de periode 1810 – 1940 in Zundert.
Algemeen
Ik heb de xml verwerkt tot een tabel met gegevens van de bruiden en bruidegoms zoals de naam, leeftijd, plaats waar het huwelijk plaats vond, het land en de plaats waar de persoon is geboren en de ouders.
De vraag die we beantwoord willen zien in de dataset is of de nabijheid van de grens meer contacten over de grens geeft. Bij huwelijken zou je dus willen zien dat gemeenten tegen de grens meer huwelijken hebben waar niet nederlanders bij betrokken zijn.
In eerste instantie heb ik 1) alle buitenlanders in de set meegenomen, daarna 2) de 10 meest voorkomende nationaliteiten en uiteindelijk alleen 3) personen uit België en Duitsland. De stap van 1) naar 2) was ingegeven door het grote aantal nationaliteiten.
| Land | Aantal | Land | Aantal | Land | Aantal |
|---|---|---|---|---|---|
| Nederland | 944714 | België | 14181 | Duitsland | 7889 |
| Indonesië | 721 | Suriname | 48 | ||
| Zwitserland | 376 | Frankrijk | 329 | Oostenrijk | 216 |
| Polen | 64 | Luxemburg | 33 | Hongarije | 32 |
| Engeland | 28 | Rusland | 16 | Guyana | 13 |
| Denemarken | 12 | Schotland | 6 | Spanje | 6 |
| Tsjechië | 6 | Canada | 5 | China | 4 |
| Ierland | 4 | Pruisen | 4 | Bonaire | 2 |
| Chili | 2 | Danzig | 2 | Egypte | 2 |
| Estland | 2 | India | 2 | Letland | 2 |
| Liechtenstein | 2 | Portugal | 2 | Zweden | 2 |
| Bohemen | 1 | Finland | 1 | Jamaica | 1 |
| Japan | 1 | Litouwen | 1 | Mauritius | 1 |
| Noorwegen | 1 | Peru | 1 | Pruissen | 1 |
| Roemenië | 1 | Slowakije | 1 | Uruguay | 1 |
De dataset heeft 968739 rijen. Als je een nationaliteit uitdrukt in percentage van het geheel is België nog bijna 1.5% en Duitsland bijna 1% maar Zwitserland zakt al naar 0.04 procent en Tsjechië 0.0006.
De stap van 2) naar 3) had vooral te maken met de onderzoeksvraag. België en Duitsland zijn letterlijk buurlanden, vanuit mijn familieonderzoek is vooral België relevant.
Na het opschonen van de dataset, met name de kolommen huwplace en bcountry respectievelijk plaats waar het huwelijk plaatsvond en land van herkomst van de bruid of bruidegom, heb ik een set gemaakt gegroepeerd op huwplace, vervolgens huwyear en tenslotte bcountry. Daar is een kolom “count” aan toegevoegd met het aantal personen van een bepaalde nationaliteit per jaar.
Om een eerste statistische exploratie te maken van de data heb ik een set gemaakt met het totaal aantal personen per gemeente, het totaal aantal Belgen en Duitsers. Van alle gemeentes heb ik via geonames de “decimal degrees” bepaald. Daarna heb ik op Google maps de “decimal degrees” gezocht van alle punten op de grens tussen Brabant en Limburg en België en Duitsland waar een straat over de grens gaat.
Met python heb ik een aantal bewerkingen uitgevoerd waardoor de set de volgende kolommen bevat:
huwplace – lat – lng – all_bg – bedu_bg – bedu_pct – dist_du_be – be_bg – be_pct – dist_be – du_bg – du_pct – dist_du – be_or_du
(De afkortingen zijn bg = brides and grooms, dist = distance, pct = percentage, be = België, du = Duitsland). Dus alle deelgroepen uitgedrukt in percentage van het totaal per gemeente en de afstand van de gemeente tot de grens. dist_be bevat dus voor alle gemeenten de afstand tot de dichtstbijzijnde grensovergang met België en voor dist_du die naar Duitsland.
Één opmerking vooraf. Brabant en Duitsland delen geen grens. Als het de bedoeling zou zijn om te kijken naar grensoverschrijdende contacten zou je Limburgse en Gelderse gemeenten tussen Groesbeek en Roermond mee moeten nemen om te zien of uitschieters als Putte in Brabant met ruim 25% Belgische bruiden en bruidegoms echt uitzonderlijk is. Maar dat is niet het doel van deze exercitie. Bovendien zijn er voldoende gemeenten met vergelijkbare parameters afstand tot België en afstand tot Duitsland.
Met de bewerkte dataset heb ik twee scatterplots gemaakt waarin de relatie tussen percentage Belgen per gemeente en de afstand tot de grens met België wordt uitgedrukt en idem voor Duitsers en de Duitse grens.
Gelukkig is de relatie tussen grens en aantal buitenlandse personen goed te zien maar er is ook verschil tussen Belgen en Duitsers.
(Klik op het plaatje voor een grotere versie.)
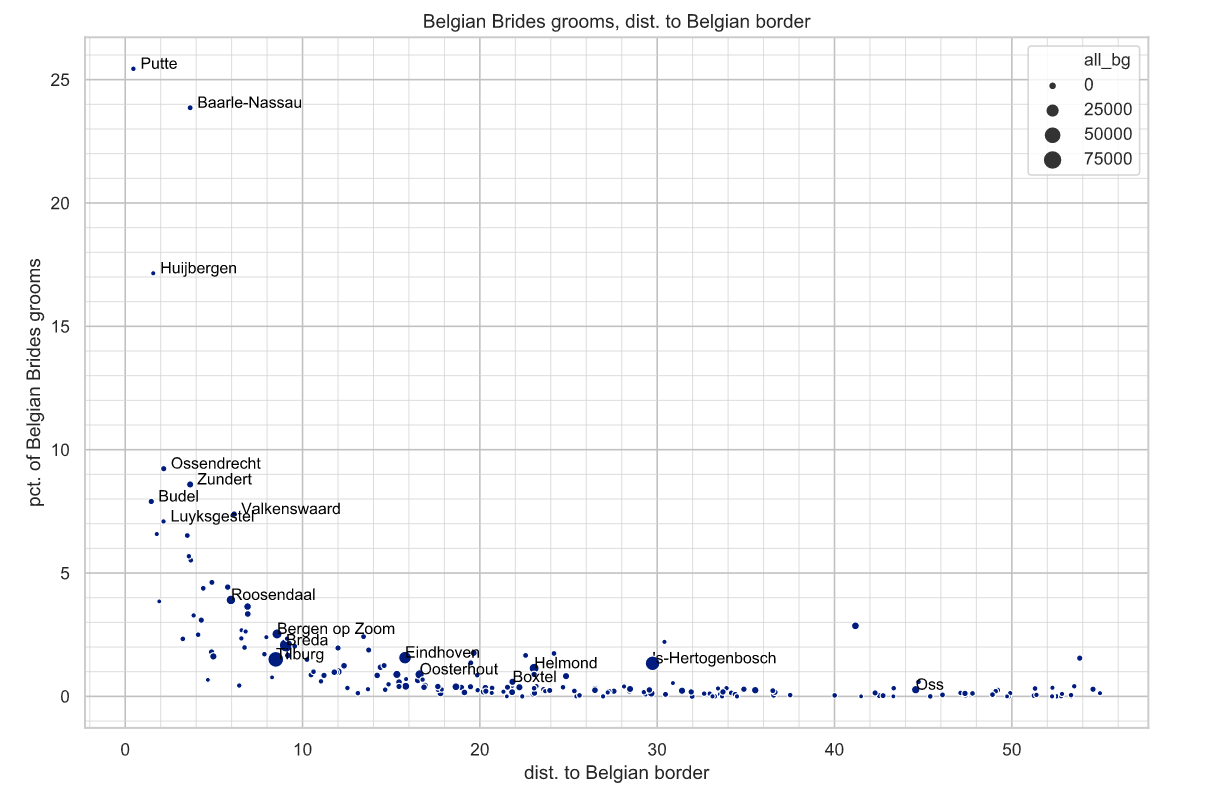
Bij plot van pct_be vs. dist_be zie je precies wat je zou verwachten. Putte, Baarle Nassau en Huijbergen, plaatsen tegen de grens staan links boven en naar mate de gemeente verder van de grens ligt neemt pct_be af.
Zundert 4 kilometer: 8%,
Roosendaal 6 kilometer: 4%,
Oss 45 kilometer: 0.3%.
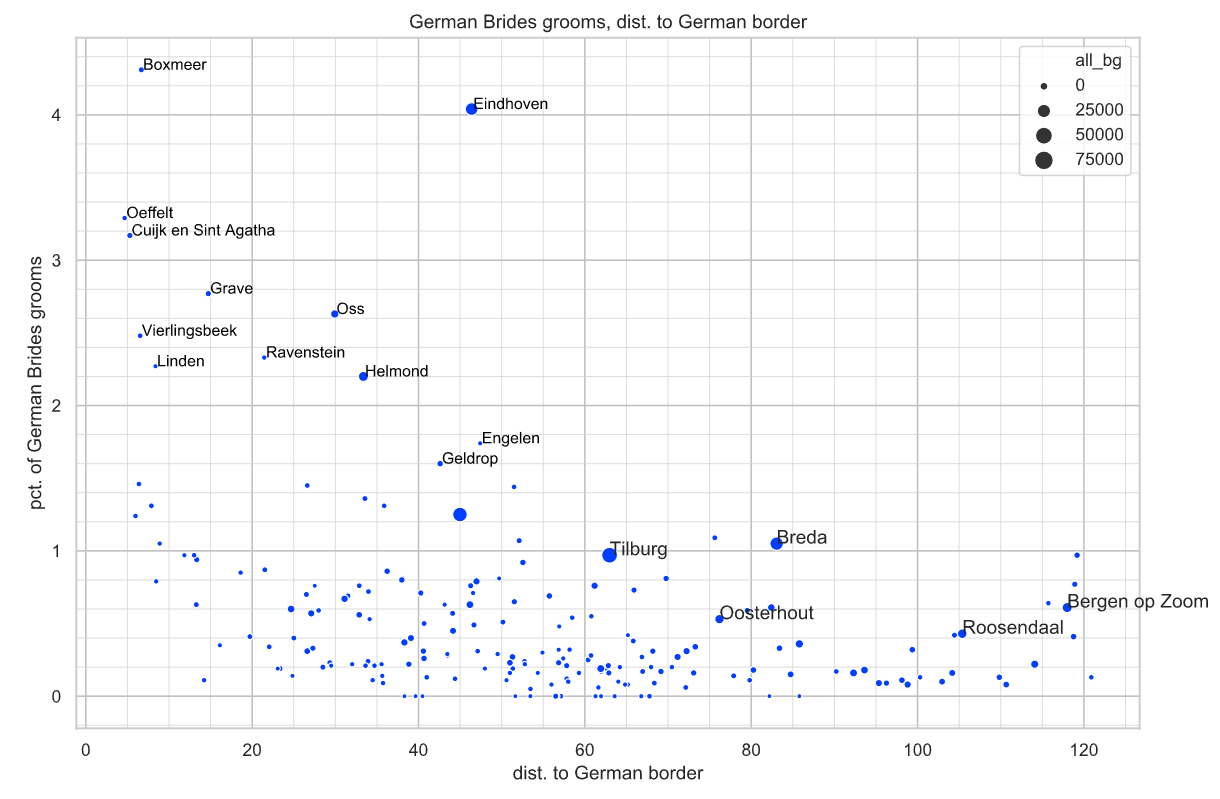
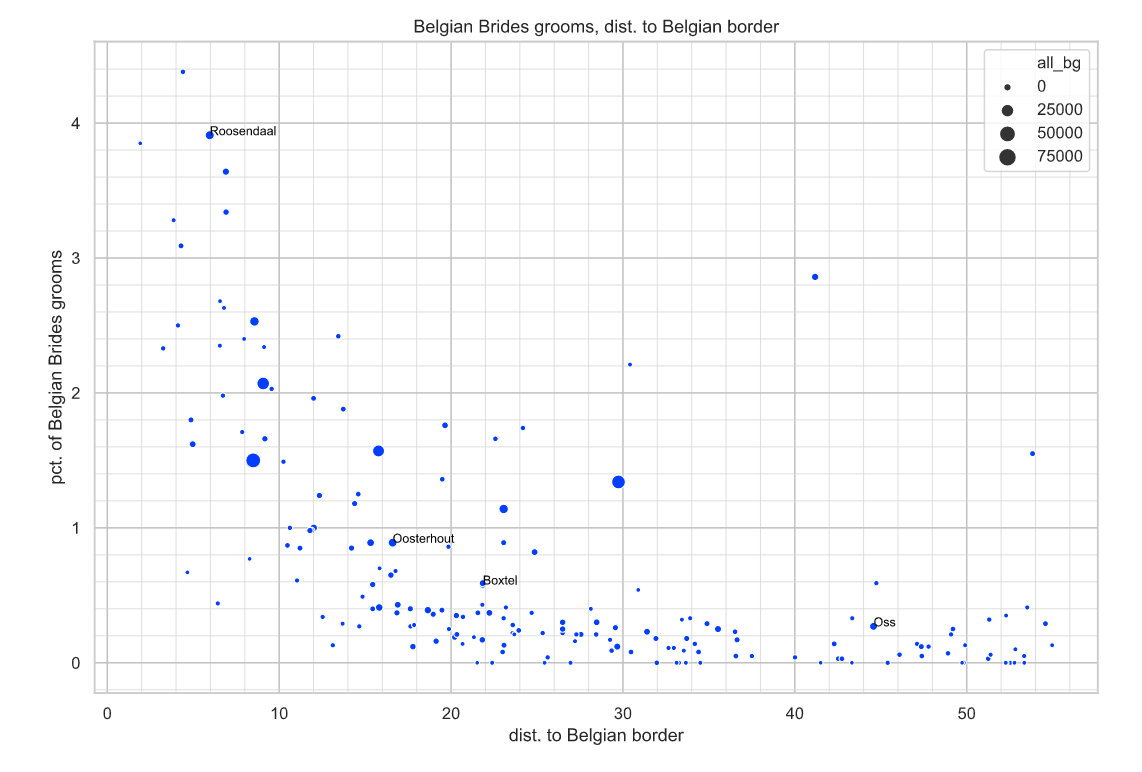
Maar bij de plot van pct_du vs. dist_du is het beeld toch een beetje anders. Om de vergelijking wat makkelijker te maken heb ik een plot gemaakt van pct_be vs. dist_be waarbij alle gemeenten boven 4.4% pct_be weg zijn gelaten. Door de vorm van Brabant en de ligging is de maximale afstand naar de Duitse grens zo’n 120 kilometer. Maar wat vooral opvalt is het verschil tussen aantal gemeenten die pct_du en pct_be tussen 0.5 en 1.0% hebben, respectievelijk 46 en 21.
Om de distributie van Belgische en Duitse bruiden en bruidegoms nog nader te bekijken heb ik twee histogrammen gemaakt met aantal pct_be en pct_du per gemeente met bins van 0.1 procent. De distributie Duitse en Belgische bruiden en bruidegoms per gemeente tussen 0 en 2 procent is verschillend.
Verder nog 4 zogenaamde swarmplots met de resultaten van een k-means analyze. K-means (k=7 in dit geval) heeft een set vectoren als input en groepeert die vectoren in clusters op grond van de afstand tussen de vectoren. Een vector in dit geval bestaat uit kolommen, pct_be, pct_du en be_dst en du_dst maar dan genormaliseerd. De verschillen tussen de afstanden is zo groot dat het te veel mee gaat wegen in de clusters. Door normalisatie worden getallen van 0 tot 120, getallen tussen de -2 en 2. Door de clustering af te zetten tegen de 4 gebruikte waarden zie dat er redelijk logische clusters zijn.
Dit soort plots zijn meer bedoeld om een indruk te krijgen van de data set niet meteen om diepgaande conclusies te trekken. Dat zie je ook als je de laatste plot bekijkt, een scatterplot van dist_be en dist_du waar de kleur het cluster voorstelt. Dan zie je bij blauw dat de meeste rechtsonder zitten maar dat er twee zijn die meer in het midden liggen. Mogelijk zijn de vectoren niet onderscheidend genoeg.
Het onderwerp van onderzoek is contacten over de grens dus de resultaten van deze analyses kan ook zijn dat ik de verhouding Nederlanders, Belgen en alle andere nationaliteiten moet bekijken.
Het verschil in distributie zou ook het resultaat kunnen zijn van een verschil in zeg maar push factoren. Zijn Belgisch Nederlandse huwelijken meer het resultaat van uitgebreidere sociale contacten over de grens en Duits Nederlandse huwelijke meer het resultaat van Duitse gastarbeiders?
Daarnaast wil ik ook de bevolkingsgroei als variabele erbij betrekken. Steden groeiden en dorpen slonken in de 19de eeuw dus zou een percentage voor Zundert in de loop van de eeuw een andere betekenis kunnen hebben. IISG heeft de dataset HDNG dus de gegevens zijn voorhanden.
https://herwaarts.nl/assets/de_grens/images/perct_duitse_bg.png Percentage Duitse bruiden en bruidegoms in bins van 0.1 procent.
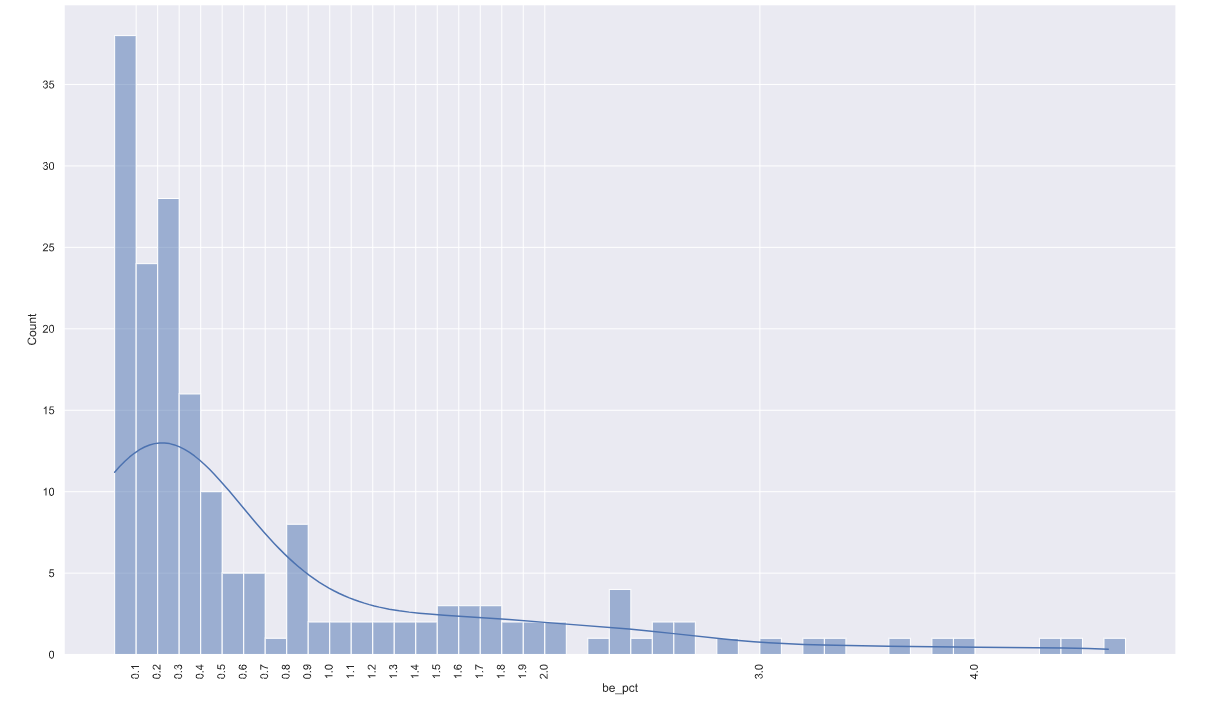
Percentage Belgische bruiden en bruidegoms in bins van 0.1 procent.
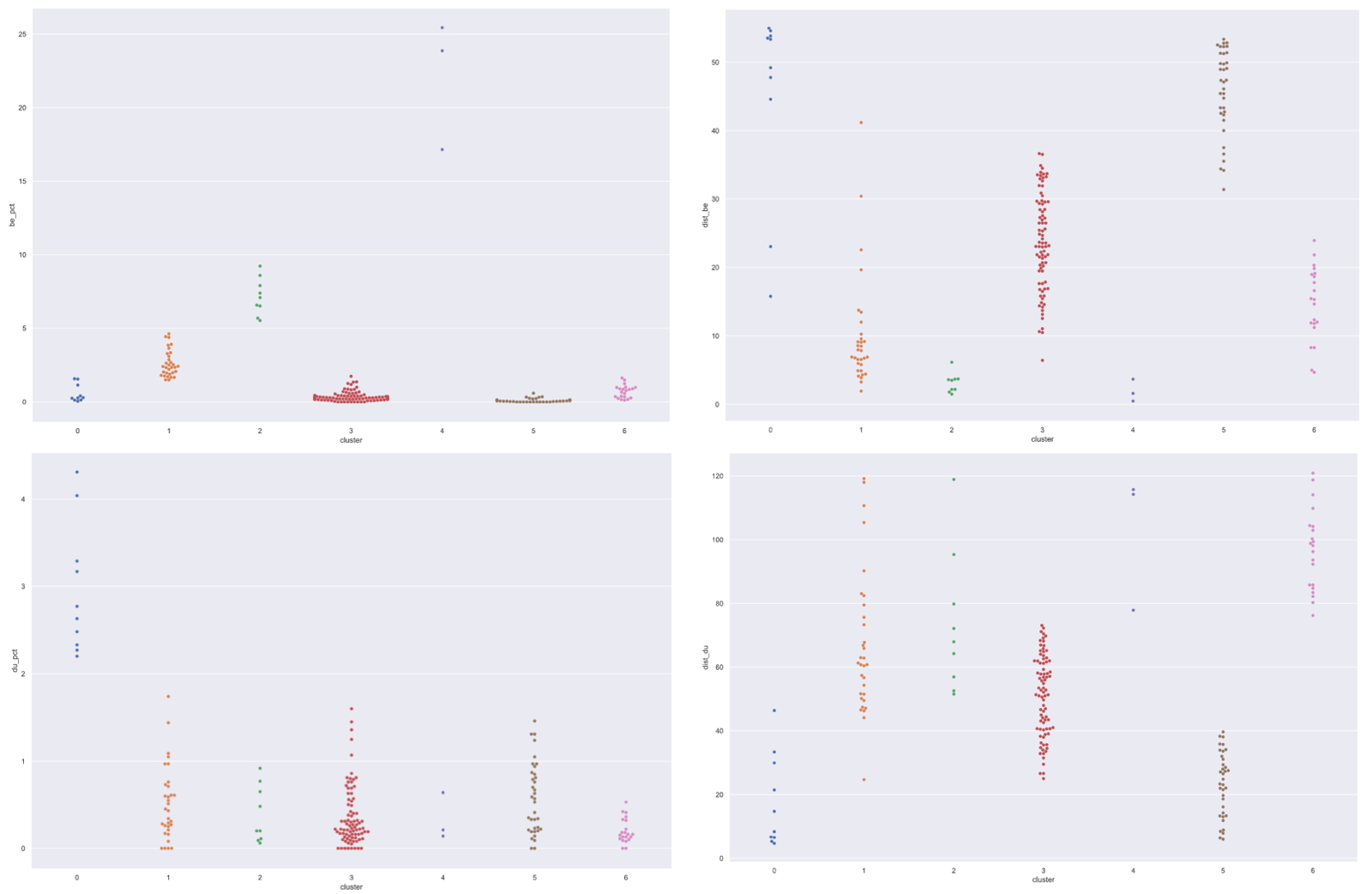
k-means (k=7) afgezet tegen de vier elementen van de vector.
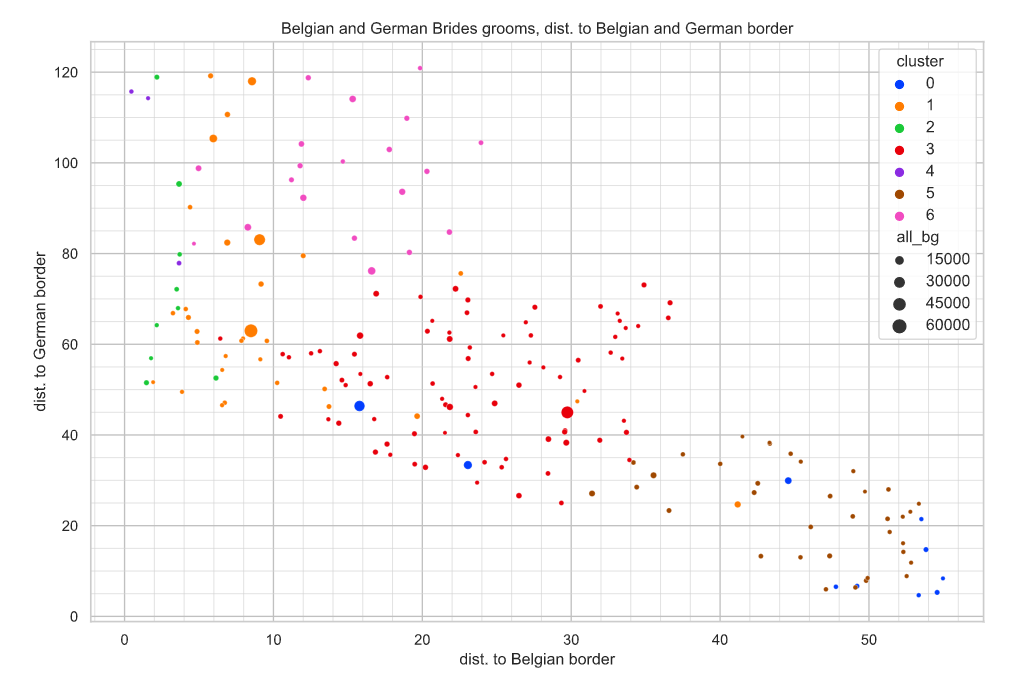
Scatterplot afstand tot Belgische grens en Duitse grens. De clusters in kleuren.
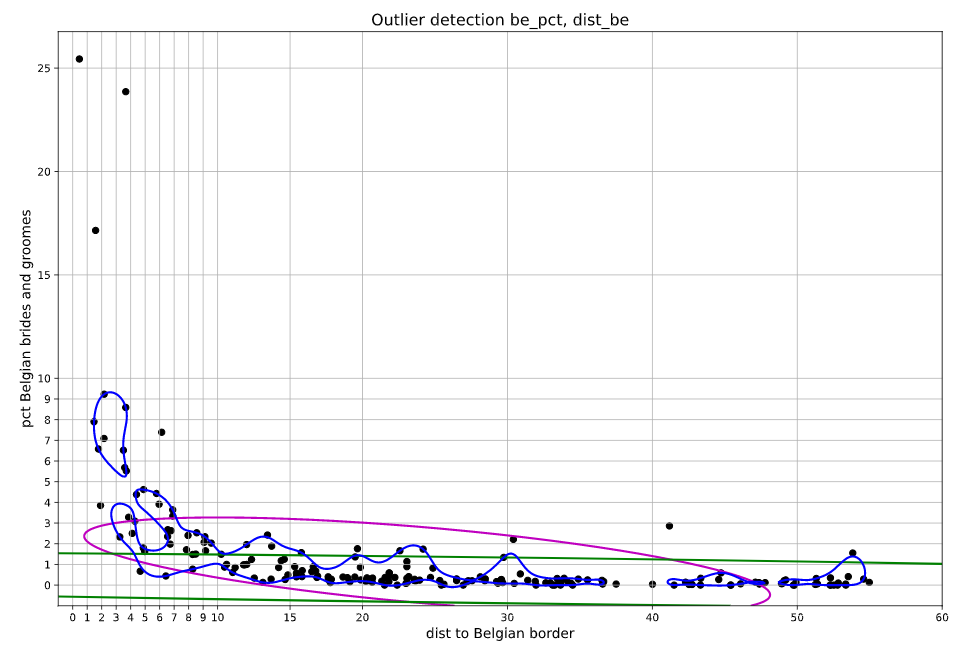
K-means is niet bedoeld om outliers te vinden maar het overzicht laat wel zien dat er een groep is die erg opvalt, groep 4. Door de co-varience te bereken van de variabelen reeksen be_pct en dist_be kun je laten zien welke be_pct, dist_be paren buiten verwachte waarden vallen. De plot hieronder laat zien dat de gemeenten in groep 4 ook hier naar voren komen. Maar er zijn nog een aantal gemeenten die opvallen. De drie kleuren zijn het resultaat van verschillende manier om de co-varience te berekenen. De blauwe lijkt in dit geval het beste resultaat.
Zundert
(Exploreer de dataset interactief.)
In de dataset Zundert heb ik het aantal bruiden en bruigoms per jaar per geboorteland gegroepeerd en geteld. Daarna uitgerekend wat het percentage is per land per jaar. De onderstaande grafiek is wat druk maar het laat wel een interessante trend zien.
Het lichte blauw is het percentage in België geboren en
het lichte grijs zijn de echte aantallen.
Het gaat dus niet om veel mensen naar naar verhouding kan het 20% van het totaal uitmaken.
De rode stippel lijnen zijn de lineaire regressie van percentages en aantallen, het aantal loopt op het percentage loopt terug.
De rode lijn vertegenwoordigt het tien jaar voortschrijdend gemiddelde (VG).
Wat opvalt is dat het VG tussen 1830 en 1840 dramatisch terug loopt en zich dan weer hersteld. Maar na 1920 begint het weer scherp te dalen. Het is wel vroeg om conclusies te trekken maar de noord zuid scheiding en de Eerste Wereldoorlog lijken effect te hebben op de contacten over de grens.
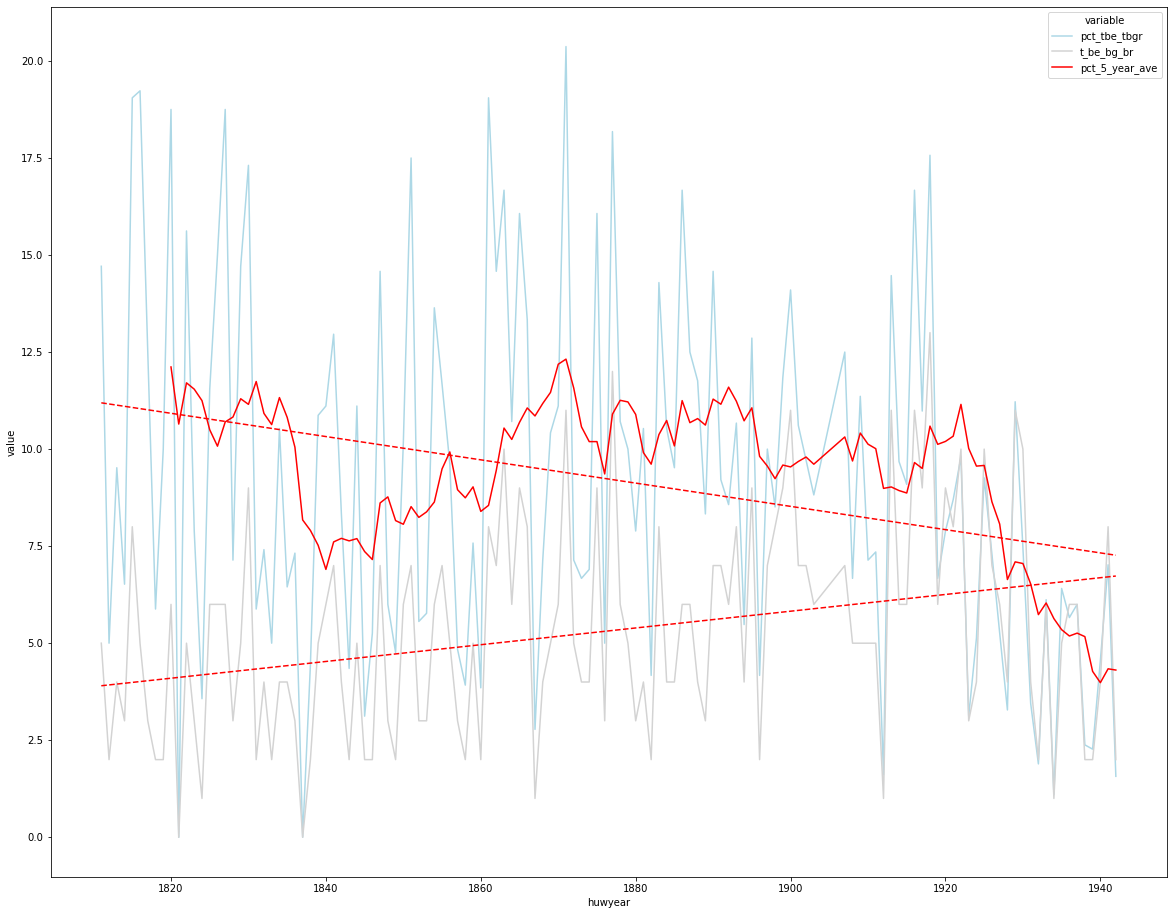
percentage en aantal Belgen, de trends over de gehele periode en het 10 jaar voortschrijdend gemiddelde.
Aangemaakt op 14 juni 2023. laatst gewijzigd op 21 July 2024 om 14:04